
核心概念
대규모 언어 모델은 종종 거짓 출력과 근거 없는 답변을 생성하는 '환각'을 보여주는데, 이를 탐지하기 위한 일반적인 방법이 필요하다.
要約
대규모 언어 모델(LLM) 시스템은 뛰어난 추론 및 질문 답변 능력을 보여주지만, 종종 거짓 출력과 근거 없는 답변을 생성하는 '환각'을 보여준다. 이는 법적 선례 조작, 뉴스 기사의 거짓 사실 생성, 의료 분야에서의 인명 위험 등의 문제를 야기한다. 감독 또는 강화를 통한 진실성 향상은 부분적으로만 성공적이었다. 연구자들은 사람들이 답변을 모르는 새로운 질문에 대해서도 작동하는 LLM의 환각을 탐지할 수 있는 일반적인 방법이 필요하다.
이 연구에서는 통계 기반의 새로운 방법을 개발했다. 의미 수준의 불확실성을 측정하는 엔트로피 기반 추정기를 사용하여 임의적이고 잘못된 생성물인 '환각'을 탐지한다. 이 방법은 특정 단어 순서가 아닌 의미 수준에서 불확실성을 계산하여, 사전 지식 없이도 새로운 데이터셋과 과제에 적용할 수 있다. 프롬프트가 환각을 생성할 가능성을 탐지함으로써, 사용자가 LLM을 신중하게 다뤄야 할 때를 이해할 수 있게 하고 LLM의 신뢰성 문제를 해결할 수 있는 새로운 가능성을 열어준다.
要約をカスタマイズ
AI でリライト
引用を生成
原文を翻訳
他の言語に翻訳
マインドマップを作成
原文コンテンツから
原文を表示
www.nature.com
Detecting hallucinations in large language models using semantic entropy - Nature
統計
LLM 시스템은 종종 거짓 출력과 근거 없는 답변을 생성한다.
법적 선례 조작, 뉴스 기사의 거짓 사실 생성, 의료 분야에서의 인명 위험 등의 문제를 야기한다.
감독 또는 강화를 통한 진실성 향상은 부분적으로만 성공적이었다.
引用
"Answering unreliably or without the necessary information prevents adoption in diverse fields, with problems including fabrication of legal precedents or untrue facts in news articles and even posing a risk to human life in medical domains such as radiology."
"Encouraging truthfulness through supervision or reinforcement has been only partially successful."
抽出されたキーインサイト
by Sebastian Fa... 場所 www.nature.com 06-19-2024
https://www.nature.com/articles/s41586-024-07421-0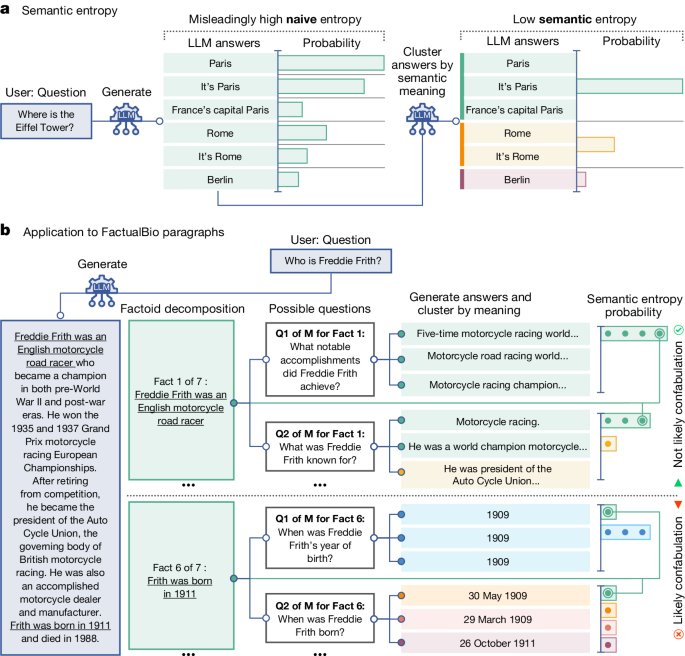
深掘り質問
LLM의 환각 탐지를 위해 어떤 다른 통계적 접근법을 고려해볼 수 있을까
환각을 탐지하기 위해 다른 통계적 접근법으로는 KL 발산(Kullback-Leibler divergence)이나 변이 추정(Variational Inference)과 같은 확률적 모델링 방법을 고려해볼 수 있습니다. 이러한 방법은 LLM이 생성한 출력과 실제 데이터 분포 사이의 차이를 측정하여 환각을 식별하는 데 도움이 될 수 있습니다.
LLM의 환각 문제를 해결하기 위해 감독 및 강화 학습 이외에 어떤 방법을 시도해볼 수 있을까
감독 및 강화 학습 외에 LLM의 환각 문제를 해결하기 위해 생성 모델의 학습 데이터에 노이즈를 추가하거나 데이터 증강(Data Augmentation)을 통해 모델을 더욱 강건하게 만들 수 있습니다. 또한, Adversarial Training과 같은 방법을 사용하여 LLM을 환각으로부터 보호하고 더욱 안정적인 출력을 얻을 수 있습니다.
LLM의 신뢰성 향상을 통해 어떤 새로운 응용 분야를 개척할 수 있을까
LLM의 신뢰성 향상을 통해 의료 분야에서의 응용 가능성이 크게 확장될 수 있습니다. 예를 들어, 의료 영상 분석에서 LLM을 사용하여 정확한 진단을 도와주는 시스템을 구축할 수 있습니다. 또한, 법률 분야나 뉴스 기사 작성과 같이 신뢰성이 요구되는 분야에서도 LLM을 안전하게 활용할 수 있게 될 것입니다.
0